How NVIDIA H100 GPUs on CoreWeave’s AI Cloud Platform Delivered a Record-Breaking Graph500 Run
The world’s top-performing system for graph processing at scale was built on a commercially available cluster.
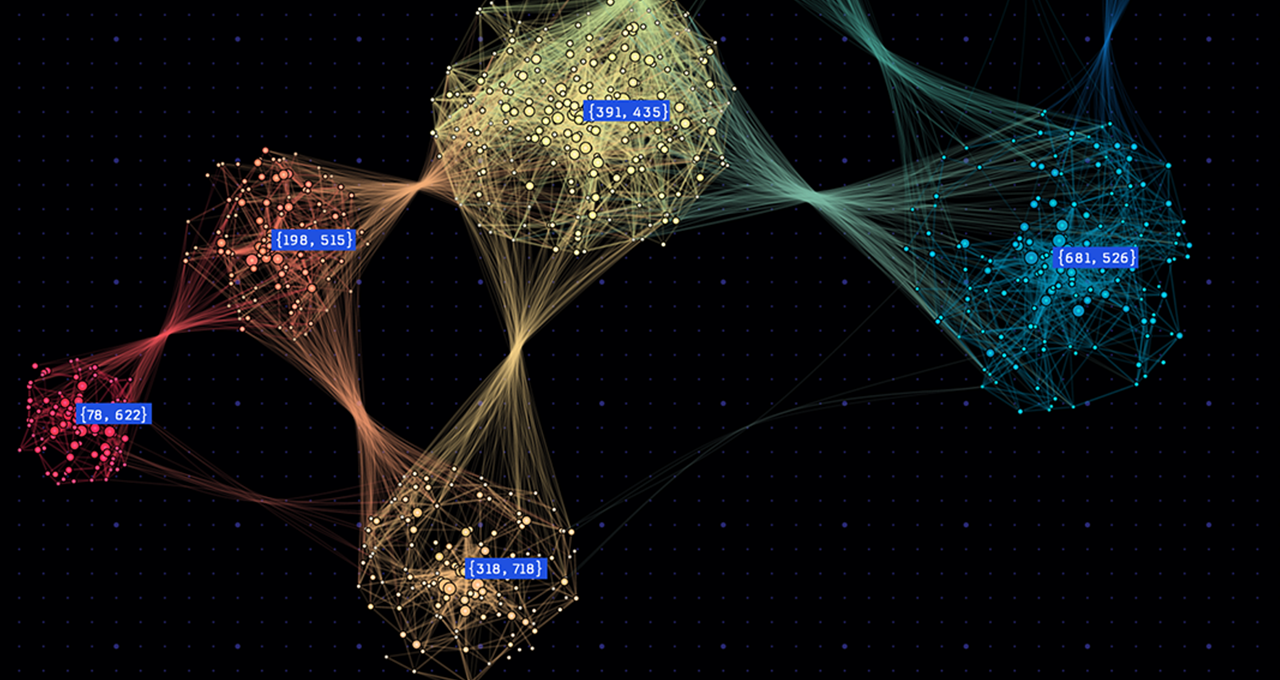

The world’s top-performing system for graph processing at scale was built on a commercially available cluster.
Reducing the number of experts per GPU : Distributing experts across up to 72 GPUs reduces the number of experts per GPU, minimizing parameter-loading pressure on each GPU’s high-bandwidth memory. Fewer experts per GPU a…

When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works .

When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works .

Score a massive amount of extra storage with this external Seagate hard drive deal

Follow Tom’s Hardware on Google News , or add us as a preferred source , to get our latest news, analysis, & reviews in your feeds.

An OptiScaler pre-alpha demo shows improved visual stability over legacy FSR frame gen.

Black Forest Labs — the frontier AI research lab developing visual generative AI models — today released the FLUX.2 family of state-of-the-art image generation models.

Although cheaper than HBM4 or HBM4E, SPHBM4 still requires stacked HBM DRAM dies that are physically larger and therefore more expensive than commodity DRAM ICs, an interface base die, TSV processing, known-good-die flow…

The H200 is manufactured by TSMC on its 4nm process and integrates high-capacity HBM3e memory , making it one of the company’s more complex chips. According to Reuters , H200 output remains limited because Nvidia has pri…
